
Disaster can strike at any time. Will you be ready to react quickly and efficiently? This article aims to show how the application architecture, especially the deployment architecture, can help us prepare for DR.
System Availability (and SLA)

System Availability is a metric that tells us how long the system works and is available during the year. It is expressed as a percentage or a fraction. We can set this metric both for the entire system and for individual components individually. If we have availability at the level of 99.0%, the system does not work for 3 days a year, 99.99% is 52 minutes a year, and 99.9999% is only 31 seconds a year. When setting such a metric for the entire system, we must first do it for individual components. These components within the system are connected either in series or in parallel. For example, if we have an application server connected to the database, it is a serial connection, the resultant SA will then be the product of these two components. It will definitely be lower than these values for these components. However, in the case of a parallel connection, the resultant SA can be calculated using the formula: A = 1 – (1 – Ax)N. For example, we have an application server and put the second one next to it, both of them handle the same traffic. If we take servers with SA at 99.0%, it turns out that the result is 99.99%. If we have three servers, the result is already 99.9999%. Although each of them may not work for 3 days a year, the resultant is really high.
SLA (Service Level Agreement) – It is an obligation towards the users or the customer that the system we deliver will be available with a specific SA.
How do I know if the system has stopped working?
To check this, Health checks are used and linked to the monitoring tool. Health checks can be verified on several levels. It can be checked at the hardware level, e.g. we check if the network traffic works and on this basis, we determine if the server works. We can check health checks at the level of the virtual machine hypervisor, if we use virtual machines, then the hypervisor tells us whether the virtual machines that we have running are functioning. We can also have health checks at the application level, we probably have an application that has some API over HTTP, we prepare a point in this application that will be used to monitor the health state of this application. We attach it to monitoring and monitoring will ask about this and point at regular intervals and determine the status of the application. Of course, if the monitoring finds, according to our rules, that the system has stopped working, it can inform us – the notification mechanism, it can also start the mechanism of automatic system recovery.
General application architecture
The architecture of the web application consists of three main elements. The first item is the user. We also have a frontend, it can be a website, a mobile application – there must be some business logic there. Frontend, on the other hand, communicates via API with the backend – i.e. the third element. In the simplest case, it will be one server in which we will have our application – also with some business logic. In addition to the server, we will have a database and a file system where we store files, e.g. that the user has uploaded to the system. If all of this is on one server, the maintenance costs will be low, but it will also be very risky. If the frontend stops working, it is a minor problem, because all you have to do is release a patch and everything will be back to normal. On the other hand, if the application server stops working on the backend, it’s all there.
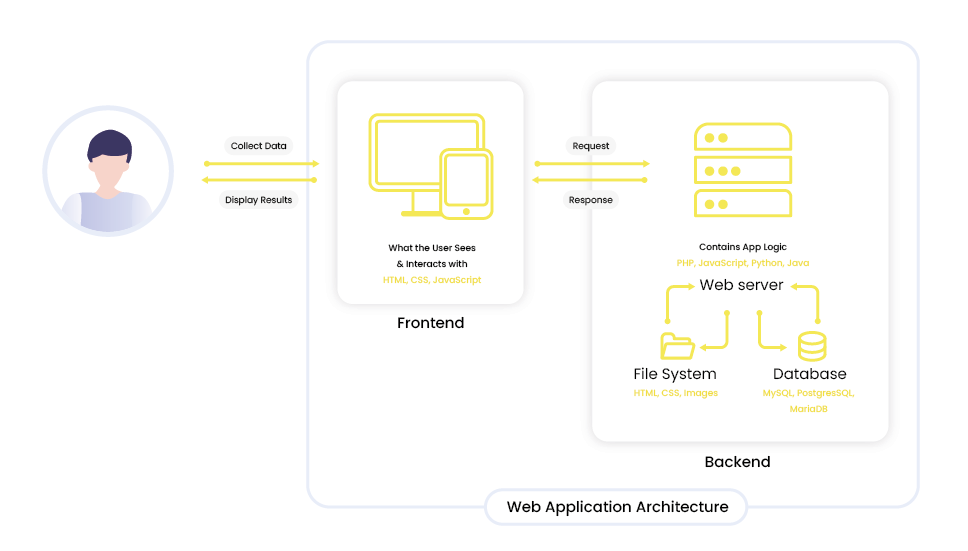
If we lose the entire server, it’s a total disaster. It’s the same with the filesystem and the database. To prevent this from happening, it’s best to separate it into at least a separate application server and a separate data layer. And the ideal solution is to separate it into three parts, each one separately. If we follow this solution, we get new possibilities like horizontal scaling. We can add new application servers to get a higher SA metric. If we put a server next door, another problem arises, because now we have to route traffic to two servers. Our API is certainly set to a domain, if we set our domain to resolve to two IP addresses, we will have two servers and two IP addresses that will work properly. When one server stops working, we can reconfigure the removal of the non-working IP address. The problem then arises that the client may still try to contact a server that is no longer operational. A typical solution that is used on the server-side is a load balancer. We implement a load balancer, i.e. a device that is responsible for directing requests to all available servers on the backend. Thanks to this, we do not have to worry about what IP address it will redirect us to, because the IP address will be one – it will be the IP address of the load balancer. A load balancer will be responsible for redirecting the request to the appropriate application server.
Another problem that comes up is that the load balancer is a single point of failure, so we have a new worry, not that big, but bear in mind that it may stop working.
A separate issue may arise at the data level, such that our drives will stop working. In such a situation, disk clusters (RAID 1, RAID 5), on-site backup, or at best, off-site backup, i.e. we copy data to a server in a distant location. When it comes to databases, it is worth knowing about the replica. We can put a second database next to our main database. It is a so-called standby instance. Then we configure database replication, from the master database to the standby database. It gives us additional possibilities in the fact that we can take one of these databases under maintenance even on a running system, without reducing the service availability of the entire system.
Datacenter disaster – how to defend yourself?
- If we already have backups, we have replications, it is already a bit complicated, so how to use it to perform disaster recovery? It depends mainly on what RTO we have.
- If RTO is long enough, i.e. hours or days, then we can use the “Backup and restore” strategy. For example, we have backups off-site, so we restore the system from backups. We also restore the database and file system, add an application server, add a load balancer, redirect DNS to the new load balancer and continue.
- If the RTO is shorter, for example, less than 1 hour, then we can use the “Pilot light” strategy. This strategy is based on the fact that in the backup server room only the necessary minimum infrastructure is kept. In this case, it will be the data layer, especially the database, because restoring the database is usually very time-consuming. It is ideal to have this database as a replica in a backup server room and then in the event of an incident all we have to do is add application servers, add a load balancer, redirect to DNS, and keep working.
- When we have an even shorter RTO, a good solution will be to expand what we have on the backup side, we go to “Warm standby”, prepare the entire infrastructure that can take over all the traffic at any time. In the event of an incident, we switch and continue. The problem here is that maintaining such infrastructure is expensive, we are paying for something that most of the time does not process traffic, is just a safeguard in the event of a disaster.
- We can go one step further and use “Multi-site”, then we have the application running in several server rooms, under the traffic. Unfortunately, in this case, the complexity of such a strategy increases significantly, because when all server rooms are processing records, we need to synchronize the state between these server rooms. The advantage is that in the event of a server room failure, users may not even notice it, there may be greater delays in the operation of the application, but it will be practically invisible.
You might also be interested in the previous article:
Disaster Recovery & Business Continuity
Cloud solutions (on the example of AWS) that facilitate HA and DR
To deal with these types of scenarios, we can use modern cloud solutions. For example, AWS provides its services within regions. Regions are located in different cities around the world. An AWS region comprises several data centers (availability zones), which are located quite close to each other, thus the network communication between them is very fast. On the other hand, they are also far apart from each other, to ensure that a disaster in one of these data centers will not affect the operation of the others.
What AWS services can help us achieve the goal we have?
- DNS – The Route 53 service has the function of configuring the so-called fail policies. This is a rule that uses health checks at the DNS server level itself. The DNS server checks if all Datacenters where the application is running are working. We configure certain health checks to be checked by the DNS server, when any Datacenter stops working, the DNS server stops returning IP numbers from the Datacenter in its responses. This is a very good solution when it comes to Disaster Recovery.
- ELB – The load balancer has built-in high availability within a single region, so if we decide to use it, we don’t have to worry about it anymore. It will force us to choose at least 2 availability zones on which it is to operate. This way AWS itself imposes certain solutions on us that increase the availability system.
- ASG – Auto scaling of the group. If we use server instances on the AWS side, it’s the auto-scaling group that makes sure that these instances are healthy. Auto-scaling – the group monitors the operation of the installation, sometimes in tandem with the load balancer, and when the instance stops working, the scaling group simply replaces it with a new one.
- S3 – i.e. object storage
- EFS – Filesystem, and also NFS, but distributed
- Aurora – It’s an AWS database, a solution compatible with MySQL and Postgres. Aurora stores the data in six copies, there are two copies of the data in each availability zone within the region. In addition, S3 and Aurora have the cross-region replication option, i.e. when it comes to S3, the uploaded data or file can be configured in such a way that this data is automatically copied to another region. For example, the application works in London, the off-site may be Frankfurt, the uploaded S3 file is automatically copied to the Frankfurt location after a few moments. In the case of Aurora, you can configure the cross-region read replica and in a few clicks via AWS console you can add it.
- AWS Serverless – This is a solution that shifts the responsibility for servers from us to AWS. If we use serverless, we don’t have to worry about servers. So we only deliver the code and AWS delivers the servers and takes full responsibility for making them work and for our application to run on it too.
Let’s sum it up
In case of disaster, you’ll be able to react quickly with the aid of a robust recovery plan. And cloud infrastructure will make it simple to put this strategy into action, allowing you to improve reliability and flexibility while saving time and money.
It’s easy to see why more and more companies of all sizes are switching their disaster recovery to the cloud. Disaster incidents can disrupt the availability of your workload, but you can eliminate these risks by using AWS Cloud services. You may select an effective DR approach by first identifying the business criteria for your workload. Then, using AWS services, you can build an infrastructure that meets your business’s recovery time and recovery point goals.
fireup.pro is an official Amazon Web Services Partner in the implementation of cloud computing. We have the necessary knowledge, know-how, and certified experts, providing high-quality services.


